|

Understanding through Discussion |
|
|
Register | Sign In |
|
QuickSearch
| EvC Forum active members: 64 (9164 total) |
|
| |
| ChatGPT | |
| Total: 916,742 Year: 3,999/9,624 Month: 870/974 Week: 197/286 Day: 4/109 Hour: 0/0 |
| Thread ▼ Details |
|
Thread Info
|
|
|
| Author | Topic: Genetics and Human Brain Evolution | ||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
I am new to the boards and I am interested in discussing the genetic basis of human evolution. I am specificlly interested in the evolution of the human brain over the last 2 1/2 million years. There are three main points of discussion I am proposing:
1.The genetic changes involved in the acquisition of unique human features, such as highly developed cognitive functions, bipedalism or the use of complex language. Nature - Not Found They have compared the differences betwee the human genome and that of chimpanzees, these differences, attributed to mutations, can be reduced to ratios. Bear this in mind when looking at real world genetic research into comparisons of humans (homo sapiens) and our, supposedly, closest relative the chimpanzee. 2. The genes involved and the number of changes that would be required for humans to evolve from apes. Evidence that human brain evolution was a spe | EurekAlert! One of the study's major surprises is the relatively large number of genes that have contributed to human brain evolution. "For a long time, people have debated about the genetic underpinning of human brain evolution," said Lahn. "Is it a few mutations in a few genes, a lot of mutations in a few genes, or a lot of mutations in a lot of genes? The answer appears to be a lot of mutations in a lot of genes. We've done a rough calculation that the evolution of the human brain probably involves hundreds if not thousands of mutations in perhaps hundreds or thousands of genes -- and even that is a conservative estimate." 3. The genetic basis for the three-fold brain expansion over ~ 2 million years. Evolution of the Human ASPM Gene, a Major Determinant of Brain Size | Genetics | Oxford Academic No amount of random combinations of chimpanzee genes could ever produce such a change in size and complexity. The only way it could happen is thousands of mutations in thousands of genes. I proposed this in another forum and someone suggested I try here. I await your response to my proposal of a new topic of discussion. This message has been edited by eggasai, 08-18-2005 09:46 PM
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: I know who Francis Collins is, he is the head of the Human Genome Project. I heard him discussing his new book on NPR, he left out some pretty important facts. First of all, the Chimpanzee Genome Project published the intitial seqeunce back in September of 2005. The found that the genomes of Chimpanzees and Humans was not 98%-99%, it was closer to 95%. What difference does that make? When you add up the single nucleotide substitutions, indels and chromsomal rearrangements it comes to 145 million base pairs. For these differences to have to accumulate would require 20 nucleotide fixed in the respective genomes, on average,for 7 million years. When Nature announced the publication of the Chimpanzee Genome they again said that 98% of the DNA was the same. There is just one problem with this, the paper says that single base substitutions (35Mb) are 1.29% and that they are dwarfed by the indels (90Mb)which are 3%-4%. With the mutation rate being about 2 * 10^-8 that means about 123 germline mutations per zygote. Don't believe me? Type 'chimpanzee genome' into your google search engine and the page announceing the paper will be at the top of the list. Then look up the Initial Sequence of the Chimpanzee Genome' (free online) and look up the indels. I would have loved it if Francis Collins had explained how this is possible but I doubt seriously he will. The human brain is 3 times the size of Chimpanzees, I don't think I will get any arguements to the contrary. Recently they started studying the Human Accelerated Regions, there are 49. The first one uncovered a regulatory gene involved in the developement of the cerbral cortex. When the human gene, 118 nucleotides long, was compared to the chimpanzee counterpart there were 18 substitutions. When the chimpanzee gene was compared to that of a chicken there were 2 substitutions. Chimps and chickens a believed to have a common ancestor 310 million years ago. The question arises how does such a highly conserved gene suddenly aquire 18 substitutions? Francis Collins is one of the world's leading genetic researchers, I would love to hear him explain this.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
I didn't say kilobases I said megabases and one of hte chromsomal rearrangements is 4 Mb long. The observed mutation rate hovers around 2.5 x 10^-8 which comes to 173 germline mutations per diploid generation. 145 Mb in 7 million years comes to 20 per year, fixed withing the respective genomes for 7 million years. That's not just an arguement, it's double the mutation rate estimated for several decades now. When the divergance was thought to be 99% the mutation rate dovetailed nicely but now it is impossible.
All the arguement I really need is take the mutation rate, estimated time frame and the amount of divergance.
quote: You left out the part where you tell me how the mutation got in there without killing off the offspring.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
The fact is that the standard line has been that the DNA is 99% the same in chimpanzees and humans. When it was discovered over the last 5 or 6 years, that it's actually 95%, no one seemed supprised. Because of the indels the amount of known divergance went up by between 3-4%. I am actually talking to a geneticist who says that it's no big deal, I don't see how 100 million base pairs is no big deal.
There are a lot of variable in the mutation rate, that's not really the issue here. The observed mutation rate, measured in base pairs is not going to get you 300 germline mutations permenantly fixed for 7 million years. I'm trying to tell you that this simply does not happen.
quote: It does not matter how you work the formula, the number of mutations required does not even come close to what actually happens. I cannot find an estimate of a mutation rate in any living system that nets that many germline mutations per diploid generation.
quote: We don't know, nor should we assume, that the 18 nucleotides in question are the result of mutations. Every time a nucleotide is substituted there is the danger of disease, defect or death. The nucleotide throws off the amino acid seqeunce, which throws off the protein seqeunce. That usually results in the reading frame being shut down, this one has 18 nucleotides that diverge between chimpanzees and humans. Mind you, this is in a crucial time of development, the cerbral cortex does not respond well to mutations in the regulatory genes. I see no reason that one cannot logically conclude that the differences are better accounted for by design rather then spontaneous mutations. You say there are three mutations in other species. Are you describing a functional gene that remains the same in successive generations or an altered gene in a minority of the population?
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: I want to take another look at the original post but this one caught my attention. You are quoting from a news article based on a limited study. Why don't you check out the Initial Sequence fo the Chimpanzee Genome (Nature, 2005). They found that 29% of the protein coding genes were identical, not 96%. If you want to track it down it will give you something more current and definitive then the news article you are gleaning from. I'll check back later and if you haven't responded I'll just edit and expand this post.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: You are confusing the actual paper with the Nature webpage announcing the paper. Type 'chimpanzee genome' into google and this will be at the top: "What makes us human? We share more than 98% of our DNA and almost all of our genes with our closest living relative, the chimpanzee. Comparing the genetic code of humans and chimps will allow the study of not only our similarities, but also the minute differences that set us apart." Chimp genome : Web focus : Nature mick is completely wrong about what I said. I said that Nature claimed 98% of the DNA in chimpanzees and humans is the same in the announcement of the Chimpanzee Genome paper that said 95%. Before you go around telling people I'm wrong you should be clear what it is I actually said. Did you even read the paper? If so do you think that a KA/KS > 1 in 600 genes and 40,000 amino acid seqeunces substituted is in keeping with the observed mutation rate in hominds? Also, the 5 million mutations you are glossing over total 90 Mb and dwarf the single substitutions. You are contradicting me and you have only read the abstract? You have to be putting me on, I've been going over this paper with one of the authors for months. Edited by eggasai, : Missed a point
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: What I said was that the Nature webpage announcing the Chimpanzee Genome paper claimed 98% of the DNA was the same, when the paper said 95% counting indels.
quote: Oh for goodness sakes, I don't know what got you so turned around but here are a couple of choice quotes: "Orthologous proteins in human and chimpanzee are extremely similar, with 29% being identical and the typical orthologue differing by only two amino acids, one per lineage." They are different at an amino acid seqeunce level which means that the proteins are coded differently. A single nucleotide seqeunce can shut a reading frame down, which is why a codon out of place is not just a minor variation it's most likely going to be deleterious. You do know that groups of three nucleotides are triplet codons designating the amino acid right? Then the amino acid seqeunces are translated into proteins, they are talking about amino acid sequences. They are saying that taken together 29% of the protein coding genes differ by two amino acids. I have no idea where you got the whole protein thing but it's wrong.
quote: Wrong again! They said that there 35 Mb of single nucleotide substitutions and 5 million indels and 'verious chromosomal rearrangements'. In the paper they discuss the indels that are 90 Mb taken together and more or less evenly split between the chimpanzee and human genome. There is an additional 9 chromosomal rearrangements 2 Mb to 4 Mb long totally around 20 Mb. Taken together this comes to 145 Mb.
quote: What about the probablity of a single amino acid substitution being anything other then delerious? When you add up all the amino acid seqeunces that diverge we are talking about 40,000 aminio acid sequences. That comes to at least 120,000 nucleotides and like I told you earlier a single nucleotide substitution can shut down the reading frame. The chances of an amino acid seqeunce turning into one of the amino acids of life is less then one in three. There are 20 amino acids in all living things, there are 4 nucleotides that are used to make them. 4^4 is 64 and there are 20 amino acids so that's about a 1/3 ratio. I'll give you the rest of your biology primer when you digest that much.
quote: You guys and your probability arguments...ok...you were saying...
quote: Look at the quote and we can take this up when you realize what I am talking about.
quote: Finally something at least reasonably cognizant. The high end would be 7 million years but most molecular clocks would put it under 5 mya. Prior to 2 1/2 million years ago your imaginary human ancestors stood three foot tall, had the cranial capacity of a chimpanzee and wre for all intents and purposes knuckle dragging apes. The first truely human looking hominid was Turkana Boy who stood 6 foot tall with a cranial capacity of 900 cc at adulthood which puts him well within the human range. Nevertheless, the outer limit for the chimpanzee/human split is 7 million years. That is 350,000 generations with the mutation rate at...let's see...2 x 10^-8 per diploid generation. That's 2 per 1oo,ooo,ooo nucleotides copied. The human genome is 2.85 billion nucleotides long but lets round it off to 3 billion. That is 60 per duplication and there are two geneomes, one from each of the parents. That comes to 120 per generation and believe me that is a rough estimate. This is the point, that is not the 200 nucleotides that would have had to be fixed in 350,000 generations. Mind you these mutations our ape cousins are experiencing are germline mutations which makes them inheritable, not nessacarily fixed.
quote: The protein coding genes account for roughly 1% of the human genome. That would make it 300 Mb and you are wanting 1 or 2 mutations fixed. You are obviously talking about amino acid substitutions so you should take into consideration the deleterious effects. Don't worry about calculating this the paper has allready done that for you: "Under the assumption that synonymous mutations are selectively neutral, the results imply that 77% of amino acid alterations in hominid genes are sufficiently deleterious as to be eliminated by natural selection. Because synonymous mutations are not entirely neutral (see below), the actual proportion of amino acid alterations with deleterious consequences may be higher. Consistent with previous studies8, we find that KA/KS of human polymorphisms with frequencies up to 15% is significantly higher than that of human-chimpanzee differences and more common polymorphisms (Table 3), implying that at least 25% of the deleterious amino acid alterations may often attain readily detectable frequencies and thus contribute significantly to the human genetic load." Well over 80% of mutations do nothing at all and the vast majority of the balance are deleterious. There is a rare beneficial effect, especially in highly conserved regions like the brain. So you have 100-120 bp worth of mutations. Of those 1-2 are in the actual genes, of those 3 out of 4 are going to be delerious enough to be acted upon by natural selection. That means you will need at least 4 per per diploid generation. This is the thing, the Human Genome Project has found millions of these little buggers and do you want to know what the effects are? You allready know, in the event that you don't I can provide you with an extensive list from the Human Genome Project I can even tell you how to get a free poster with them listed. Interested in a free poster from HGP?
quote: I'm just curious at this point since there is not a snowballs chance in Bagdad that this is an accurate statement. Do you usually get by with this kind of a jacked up misrepresentation of scientific literature? Have a nice day.eggasai Edited by eggasai, : transcript errors Edited by eggasai, : No reason given.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: Don't you get tired of being wrong? Nonesense, there is no such thing as a coding nucleotide. There are aminio acid seqeunces in protein coding gene have to translate into meaningfull proteins. If the chain is broken a stop codon will be inserted shutting down the reading frame. There is no actual frame, it's just an expression and if you are going to be making this kind of a fundamental mistake I'm going to have some fun with this.
quote: Whether they are deleterious or not is the key factor in whether or not they are fixed. Three out of four will be deleterious enough for there to be negative selection. That means that most of the mutations that pop up on the NS radar get zapped. Deleterious mutations do get fixed and the result is disease, disorder and death. Fundamental error #2, you don't realize the roles of deleterious effects on fixation.
quote: No, first of all you need to learn basic biology before you start pontificating about how things work:
quote: That's the first thing you got right and you didn't correct what I said, you finally understood something fundamental. Most of the protein coding gene differ by one amino acid sequence in each of the two genomes. That's a mean average with some diverging by a more.
quote: Those mutations that you are putting in the protein coding genes are probably deleterious and could shut the reading frame down. You don't seem to have a grasp of this fact so I will continue to repeat it until you do.
quote: The ones described in the paper are only the major ones, there are a lot of others. These are 2 Mb to 4 Mb in length for 20 Mb and they don't interest you even though we are talking about half as many base pairs involved as the single nucleotide substitutions.
quote: No, I don't think that nor have I said anything of the sort. It could be a single nucleotide in each of the amino acid seqeunces but if it's just one nucleotide you are limited to what kind of an amino acid sequence it involved. Like I keep telling you a single nucleotide can shut the reading frame down making the gene inoperative. Your not getting that but it's not my fault you didn't learn basic biology before you started preaching it.
quote: You are right about the sixty-four possible codons, it is 4^3=64, I was all set to compliment you on getting something right. There are 20 amino acids of life not 61, notice the three stop codons you were trying to factor in on the chart:
Codons don't code for anything, triplet codons are formed together in amino acid seqeucnes, the amino acid seqeunces are translated into proteins. You are defending your sacred evolution from creationist infidels and you don't know the central dogma of biology!? I'll give you a hint, DNA-transcription-RNA-translation. Artemis will not be pleased with you if you don't learn the central dogma. Edited by eggasai, : transcription errors
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: You guys like to exaggerate pedantic points don't you? Your buddy had one fundamental error after another but that's ok, he's an evolutionist. Anyway, when we have trudged through the pedantic biology sermons maybe you guys would like to get back on topic. You might want to clue your buddy in on the terminiology and actually read some of the literature before we start. The thread is about the genetic basis for this giant leap of evolution:
I'm glad you are so well versed in basic biology, your going to need it. Edited by eggasai, : transcript errors Edited by AdminJar, : No reason given. Edited by eggasai, : Checking out what the Mod did.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: I noticed that you are not as hypercritical about mistakes when it's one of your own. I just wonder how many creationists you have poisoned the well for, but no matter. Rest assured that the deleterious affects of mutations on neural genes is going to be discussed.
quote: Because they don't unless they come in triplet codons. Your boy Mick said that each nucleotide had at least one reading frame. I didn't see you go into spasms over that, I expect this is just a diversionary tactic while you try to get a handle on the Chimpanzee Genome paper.
quote: No they don't, amino acids code for proteins, nucleotides are just the basic element of precise amino acid sequences. I'm neither baffled nor dazzled by how you conflate that basic biology and try to magnify percieved errors. I've done this before and I know what happens when you guys are confronted with the evidence.
quote: You preach fundamentalist biology to me and make an assinine remark like that? Amino acids are composed of triplet codons which are three nucleotides called triplet codons, it just an expression really. Watson and Crick determined that codons were triplet by removing 1 or two of the nucleotides. This became the 'central dogma' of biology (DNA-trascription-RNA-translation) in their famous paper on the subject.
quote: No it's not, the amino acid sequence is translated into proteins in the ribosome...jezzz...talk about a fundamental error.
quote: I don't either, you guys need basic biology. At this point diving into the scientific literature would be worse then useless. If you learned something about comparitive genomics now you would probably learn it wrong. We can spend some time on the Biology primer, it's better then trying to explain everything about the papers we are going to be looking at.
quote: I'm glad you brought that up, you guys have no clue what a deleterious effect from a mutation is either. Why don't you forget about the synonomous/nonsynonomous ratio right now, you aren't even congnizant of it's relevance or signifigance. You need to learn what happens when a mutation happens in the amino acid seqeunce:
So why don't you elaborate on the 'central dogma' of biology? You can't continue into comparitive genomics untill you get some basic terminology down and at least a rudimentary understanding of the principles.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
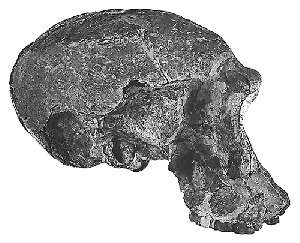
This is almost cliche, evolutionists love to cut and paste those skulls and let the illusion of gradual transition sink in. This is what the thread will be about, this is Homo habilis who stood 3 foot tall with the cranial capacity of an ape:
In 2 1/2 million years the cranial capacity had not signifigantly diverged from that of apes. The above skull is not much bigger then an apes,Then in less roughly 300 ka Turkana Boy appears suddenly along with the Homo erectus fossils. Edited by eggasai, : Had to cut the lesson short
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: Originally I said that a single nucleotide substitution in the protein coding genes could shut down the reading frame. The rest of it is a tangent, this is how the amino acid sequence codes for proteins:
The triplet codons make the amino acids. The amino acids in a specific sequence make up the 'code'. My point was that there was no such thing as a coding nucleotide, it's the amino acid seqeunce that determines the protein. Apparently, things are going to be bogged down on semanitcs and basic biology for a while. I was trying to talk about the protein coding genes but instead we are spending all our time on what a protien code is. They think I don't know basic biology, that's the real problem. Edited by eggasai, : transcript errors
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: No problem, I'm actually enjoying the basic biology primer.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: Still the cranial capacity becomes central to the definition Hominids based on the cerebral rubicon. Cranial capacity is the most distictive feature of the genus Homo, the various definitions within that genus reflect this basic concept.
quote: Gorillas stand pretty tall but their cranial capacity still isn't as big as a chimpanzees, who stand about 3 foot tall. The cerbreal rubicon has long been that main morphological traits that distinquishes hominids from apes. It has become increasingly clear to me that the not all of the hominids belong in the genus Homo. Cranial capacity still marks a clear line of demarkation.
quote: Dimomorphic variance also translates into cranial capacity differences. Hablines generally range from 510cc to 775cc and besides bipedal frames they are clearly knuckle dragging apes.
quote: The trend in the early hominids suggests to me that the trend in ape lineages was a decrease in absolute brain size. Every ape skull dug up in Africa from prehistory is automatically put in human lineage. There should be a concerted effort to determine ape lineage but the need for transitionals takes preferance.
quote: What we really have for the Austropithecenes is fragmentary peicemeal compositions. There is no genuine absolute brain/body size ratios. With the habilines they are well below the cranial capacity for humans and in some cases for the Homo genus. What you are looking at in ape lineages is a decrease in cranial capacity and a loss of bepediality. That's why this gets so convoluted, too often they are automatically considered human ancestors rather then ape.
quote: The austrophithecines average slightly above that of a modern ape. The overall brain size did not double from the Austropithecines to the habilines. Homo habilis had a cranial capacity below 600cc while the austropithecines has a cranial capacity about 400cc. The cranial capacity does not actually make a signifigant jump until Homo habilis where it goes from under 600cc to close to 1000cc. What needs to be understood is that the austropithecines and hablines are actually a mixture of gorilla and chimpanzee ancestors. The human ancestors are actually the Homo erectus fossils.
|
||||||||||||||||||||||||||||||||||||
|
eggasai Inactive Member |
quote: The amino acid seqeunce is the code the proteins are translated from in the ribosome.
quote: I don't know what you think the problem is here but amino acids are translated into proteins. The amino acids determine the protien chain but they have to be translated into proteins, that is about as basic as it gets.
quote: Yes they do, the amino acid is defined by the triplet codons, remove a condon and you got nucletides.
quote: No, the nucleotides make the triplet codons of the amino acids. Nucletides don't code anything in and of themselves and your spliting semantical hairs. This is twice you tried to contradict me and then elaborated from there on a tangent.
quote: That's kind of funny, most of the basic biology we are discussing could be covered in one post. I don't know if conflating the basic biology is just a rethorical tactic or you actually believe what your saying. This all started with the misconception that a nucleotide has some intrinsic coding quality. I mentioned in passing that a single nucleotide substitution could get the reading frame shut down. I was contradicted and told that every coding nucleotide has at least one reading frame. Terms like; reading frame, coding sequence and protein sequence are just expressions. The basic principle was summed up as DNA-transcription-RNA-translation (aka the central dogma of biology) A debate is impossible because no one seem cognizant of this ubiquitious principle in biology. Basic errors are actually being made not because of my misunderstanding but an attempt to correct and contradict me. The original point was that the protein coding genes show differences at an amino acid sequence level. One regulatory gene 118 nucleotides long has diverges from chimpanzees by 18 nucleotides. The same regulatory gene when comparing chimps to chickens has 2 substitutions which represents 310 million years. When this point couldn't be answered the discusssion was derailed with this...basic biology debate. Edited by eggasai, : transcript errors having a deleterious affect in the alphanumeric word codeing sequences. You know...typos.
|
||||||||||||||||||||||||||||||||||||
|
|
Do Nothing Button
Copyright 2001-2023 by EvC Forum, All Rights Reserved
![]() ™ Version 4.2
™ Version 4.2
Innovative software from Qwixotic © 2024