|

Understanding through Discussion |
|
|
Register | Sign In |
|
QuickSearch
| Thread ▼ Details |
|
Thread Info
|
|
|
| Author | Topic: Introduction to Genetics | |||||||||||||||||||||||||||||||||||||||||||
|
crashfrog Member (Idle past 1488 days)  Posts: 19762 From: Silver Spring, MD Joined: |
Also, I'm assuming the DNA strand doesn't break for this exchange to take place, break apart and come together again, so it isn't exactly right to say that a whole GENE is being moved, is it? It actually is being broken when these kinds of re-writes are happening. It's being snipped, moved, and re-combined. Doing this safely with controlled results is pretty important to the continued health of the cell, as you might imagine, so it happens to be the case that quite a bit of the enzymes "at work" in the cell's nucleus are involved in this process. But the fact that this happens in all species - and that the enzymes for doing it are relatively similar across widely different species, and therefore compatible - gave us our first chemical tools for studying DNA sequences and manipulating them. The same enzymes that snip DNA in cells are how we produce those "black bar" pictures you asked about before. How that actually happens is a matter of the chemistry of the DNA molecule itself, which I think we've all decided is a little out of scope right now, but I can elaborate at your request.
|
|||||||||||||||||||||||||||||||||||||||||||
|
sfs Member (Idle past 2555 days) Posts: 464 From: Cambridge, MA USA Joined: |
Faith writes:
Call it uncommon, although not extremely rare -- it happens in humans in something like a few births per thousand. It's not the norm, and is best ignored when trying to get the basic picture in focus. As someone pointed out, every rule in biology has exceptions (including the rule that all rules have exceptions).
But let me ask: Is this swapping a rare occurrence or fairly common?
|
|||||||||||||||||||||||||||||||||||||||||||
Faith  Suspended Member (Idle past 1466 days)  Posts: 35298 From: Nevada, USA Joined: |
Thanks for everybody's input on chromosomes. I'll never get all of this straight I'm sure but some of it is sinking in.
I did go look up meiosis and mitosis and watched some animations, more than once. Thought I knew about cell division all the way back in high school already, but I'm finding that it's hard to retain the details in mind after watching even many times. Just getting old I guess. But watching them did make me aware that chromosomes aren't just arbitrary bits of DNA, they have a structure, even down to the "centromere" and the cell division process acts upon them rather strikingly. Could get bogged in detail if I pursue any of this further so I'm going to go on to another question.
|
|||||||||||||||||||||||||||||||||||||||||||
|
Faith Suspended Member (Idle past 1466 days) Posts: 35298 From: Nevada, USA Joined: |
OK, we can think about the question you answered, Crash. I'm skipping over #3 for now just because it doesn't interest me at the moment.
[qs] Do you ever actually look at the DNA itself or are you looking at some sort of indicator, model, or whatever you call it that you somehow derive from the cell? I know a DNA portrait as it were is often represented by some sort of bars that to me are indecipherable. Do I have to learn what those mean in order to get answers to the sort of questions I'm asking? You post a picture of a test tube with some white filaments at the top. That's the DNA out of the peas?
Crashfrog writes: In this form, it doesn't tell anybody much at all. It's just a slimy fiber. Learning to read this - for that matter, learning what it did - was the central task in biology and biochemistry for about 50 years. As a field, we're largely moving away from "black bars"-type techniques in molecular biology and more into direct sequencing. Actually I'd say that we already have. So, no, you won't have to learn how to read one of those. But what IS direct sequencing? You look at the DNA strand under a microscope and count off the chemicals? Taq seems to be saying something somewhat different:
Taq writes: Most sequencing uses Sanger sequencing (as cited above). DNA profiling uses PCR to amplify short tandem repeats (STR's), and the gel then separates these short sequences by size. Those will produce the bands you see on some of those gels, such as this one: [he inserts a link here that I can't get to work] There is also RFLP techniques that look at larger chunks of DNA and how they are chopped up by different enzymes: [and another unfunctioning link] IOW, there are many ways of doing DNA fingerprints, and not all of them require direct sequencing. PCR and endonucleases are two indispensible tools used in this type of work, so if you want to understand what is going on you should really learn what those tools are and how they are used. I doubt I'm going to get very far into learning much about the secondary techniques involved in reading DNA. My questions come more from wanting to be able to visualize the DNA strand and what's going on there more than anything else. There are plenty of Wikipedia articles that do give diagrams that demonstrate various DNA events, such as different kinds of mutations. Maybe I don't know what I'm asking. But again: In direct sequencing are you actually looking at an actual DNA strand and what does it look like? I'm sure the diagrams are accurate enough but the reality must be a lot messier.
|
|||||||||||||||||||||||||||||||||||||||||||
|
crashfrog Member (Idle past 1488 days) Posts: 19762 From: Silver Spring, MD Joined:
|
That's the DNA out of the peas? Yeah, the white stringy stuff. Like I say in its raw form it's not of much use.
But what IS direct sequencing? You look at the DNA strand under a microscope and count off the chemicals? The bases of DNA are far too small to see like that. We use chemistry, electronics, and computers to sequence DNA bases. There are a couple of ways to do it but they're all based on PCR - the polymerase chain reaction, a combination of chemicals, an enzyme called Taq polymerase, which is where our friend Taq derives his username, and a machine called a "thermocycler" that basically gets hot and cold on command. (The PCR reaction is controlled by temperature.) What does PCR do? It's a way to chemically "amplify" DNA. When you extract the DNA from a single human cell, for instance, you get two copies of each of 23 human chromosomes - and that's it. 46 molecules in total. That's not nearly enough to do much chemistry on, so PCR was developed as a way to take a sample of DNA and duplicate it over and over again, making a perfect copy each time. 1 DNA molecule becomes 2, 2 get copied to 4, 4 get copied to 8; if you do it about 30 times you turn a single DNA molecule into one billion identical copies. PCR really revolutionized biology and biotechnology, it's the basis of the "biotechnology revolution" and fundamentally made genetic engineering and other applications possible. The sequencing technologies we use are adaptations of this technology. If you're interested in the chemistry I can elaborate.
My questions come more from wanting to be able to visualize the DNA strand and what's going on there more than anything else. Sure. The most important thing to visualize is the "Watson-Crick" pairing - that, if you know the bases along one strand of the DNA, you can reconstruct the other strand by matching each base with its Watson-Crick pair: A to T, C to G. If you have two strands of DNA, you can copy it by separating the strands and then, using each strand as a template, reconstructing the complimentary strand. Now you have two copies, instead of just one. Every time you do that, you double your DNA. Hopefully it's a little more clear - after direct sequencing, you're not looking at a DNA strand, you're usually looking at a computer. For instance, all we do in my lab is sequencing, and the output we get are text files on hard drives. Each text file - sometimes these are gigabyte files - are just lists of letters. ATGC, corresponding to the bases. It's much more useful to have it that way, because now we can use computer programs to look for sequences, put them into databases, and match or compare them to sequences that are already there. That's all incredibly useful and it's part of the field called "bioinformatics."
|
|||||||||||||||||||||||||||||||||||||||||||
|
Faith Suspended Member (Idle past 1466 days) Posts: 35298 From: Nevada, USA Joined: |
That's all really helpful, sorts a bunch of stuff out for me. Thanks. Now I can see I'm going to have some questions about the actual sequences, the CAGT sequences and what they tell you.
For starters let me guess, you don't sequence an entire gene, which is too huge, but there are parts of the sequence that give you useful information about it?
|
|||||||||||||||||||||||||||||||||||||||||||
|
crashfrog Member (Idle past 1488 days) Posts: 19762 From: Silver Spring, MD Joined:
|
For starters let me guess, you don't sequence an entire gene, which is too huge, but there are parts of the sequence that give you useful information about it? Genes are small enough to be readily sequenced - about 3000 base pairs. If you have information about what sequence that gene already has - usually because you've already sequenced the orthologous gene in another related organism - then it's really easy to pull out that gene and read it directly. If you're trying to sequence a gene for which you have no pre-existing sequence information - de novo sequencing, that's called - then it can be harder to get it's sequence. But it's not impossible, just hard. It's a lot more time-consuming to sequence the entire genome of an organism, that's every base pair on every chromosome. In human beings, for instance, that's 3.6 billion base pairs. But as the technology marches along we've dramatically improved sequencing times. The project to sequence the entire human genome (appropriately, the "Human Genome Project") took 11 years and millions of dollars. With current technology we could do it in a few days for about $5,000. Of course, just the string of bases doesn't immediately tell you a whole lot. It all looks like random noise. To get something useful out of it the genome has to be annotated, that is, we have to associate parts of the DNA sequence with their function, with traits and alternative alleles - with whatever information we already have about what part of the DNA does what. That's called the "annotated genome" and producing it for humans and other organisms is what we're currently doing in molecular biology. Here, you can take a look if you like:
http://genome.ucsc.edu/cgi-bin/hgGateway This is the Annotated Genome Browser, which is a way to browse the information we've associated with the DNA sequence of an organism (human, in this case.) You don't need to put anything into the fields, just click "submit". For whatever reason it takes you to human chromosome 21 by default. Since it's primarily a research tool, it'll be like drinking from the firehose for you, but don't be discouraged, most of the scientists who look at this are so specialized in one particular area of the genome that most of the information presented here isn't very meaningful to them, either. It's just to give you a sense of what the information we're generating looks like, or can be displayed as. Looking at the genome browser will probably give you like a million questions, I just present it so that you can see what kind of sequence and annotation data is being generated by scientists in molecular biology.
|
|||||||||||||||||||||||||||||||||||||||||||
|
Faith Suspended Member (Idle past 1466 days) Posts: 35298 From: Nevada, USA Joined: |
Hello Crash,
Sorry I've been so neglectful of this thread. Hope I can get back to it with more concentration soon. Didn't want to let things get out of order here but maybe it's OK as long as the subtitles identify the topic. I really would like to know about "Junk DNA" and was going to skip to that question anyway when I saw Dr. A's post with the diagram of the Human Genome here: EvC Forum: Flood Geology: A Thread For Portillo It doesn't even mention Junk DNA. Can you explain? Thanks ABE: The Wikipedia article on Noncoding DNA seems to suggest that the term Junk DNA applies to all DNA that does not produce protein. Non-coding DNA - Wikipedia Reading through this site I see a description of Pseudogenes that fits my understanding of Junk DNA:
PseudogenesPseudogenes are DNA sequences, related to known genes, that have lost their protein-coding ability or are otherwise no longer expressed in the cell. Pseudogenes arise from retrotransposition or genomic duplication of functional genes, and become "genomic fossils" that are nonfunctional due to mutations that prevent the transcription of the gene, such as within the gene promoter region, or fatally alter the translation of the gene, such as premature stop codons or frameshifts.[11] Pseudogenes resulting from the retrotransposition of an RNA intermediate are known as processed pseudogenes; pseudogenes that arise from the genomic remains of duplicated genes or residues of inactivated genes are nonprocessed pseudogenes.[11] I don't see an indication of what percentage of the Genome is pseudogenes. Then there is a discussion of Junk DNA farther down which also fits my understanding, that is, formerly functioning DNA that was killed by deleterious mutations:
"Junk DNA" is a term that was introduced in 1972 by Susumu Ohno,[30] who noted that the mutational load from deleterious mutations placed an upper limit on the number of functional loci that could be expected given a typical mutation rate. Ohno predicted that mammal genomes could not have more than 30,000 loci under selection before the "cost" from the mutational load would cause an inescapable decline in fitness, and eventually extinction. This prediction remains robust, with the human genome containing approximately 20,000 genes. Junk DNA remains a label for the portions of a genome sequence for which no discernible function had been identified.
Obviously I could think a lot more carefully about all of this than I have and hope I can eventually. Meanwhile it looks like a starting point. P.S. I'm counting on you to be able to reduce this to a practical, manageable, digestible summary for the nonscientist. Edited by Faith, : No reason given. Edited by Faith, : No reason given. Edited by Faith, : Add P.S.
|
|||||||||||||||||||||||||||||||||||||||||||
|
Taq Member  Posts: 10038 Joined: Member Rating: 5.3 |
Didn't want to let things get out of order here but maybe it's OK as long as the subtitles identify the topic. I really would like to know about "Junk DNA" and was going to skip to that question anyway when I saw Dr. A's post with the diagram of the Human Genome here: EvC Forum: Flood Geology: A Thread For Portillo It doesn't even mention Junk DNA. Can you explain?
Labelling something as "junk DNA" doesn't tell us a whole lot about it. It doesn't tell us what function it may have had (e.g. pseudogenes), if it is associated with genes (e.g. introns), if the junk DNA came from transposons, etc. Also, a transposon (SINE's and LINE's) can be junk DNA and it can also have function as a regulator of surrounding genes. The chart that Dr. A used was focusing more on the idea of alleles which focus more on the protein coding sections of the genome which only account for 3% of the genome. It was not meant to show how much junk DNA there is.
ABE: The Wikipedia article on Noncoding DNA seems to suggest that the term Junk DNA applies to all DNA that does not produce protein. That's a very poor description since transcription factors are noncoding DNA but they have very important functions and are nothing close to junk DNA. I would classify junk DNA as disposable non-coding DNA. That is, if that DNA were removed or it's sequence randomly changed it would not have a perceptible effect on phenotype or fitness. Many ERV's, transposons, and pseudogenes would fall under this category while important DNA regulators would not.
I don't see an indication of what percentage of the Genome is pseudogenes. Most estimates I have seen are in the ballpark of 20,000 to 75,000 pseudogenes in the human genome. Not sure about the number of bases, but I can't image that it is much more than coding DNA at about 3% (maybe as high as 10% or as low as 1%?). sfs might have more info on that since he was directly involved in the human genome project (and was an author on the human genome paper if memory serves). But of course, all of this comes down to the question of whether a stretch of DNA has important function, and that isn't completely determined by the DNA sequence alone. You need more data which the ENCODE project is currently working on. "The National Human Genome Research Institute (NHGRI) launched a public research consortium named ENCODE, the Encyclopedia Of DNA Elements, in September 2003, to carry out a project to identify all functional elements in the human genome sequence."http://www.genome.gov/10005107 However, ENCODE suffers from salesmanship, IMHO. In their latest publication they are claiming that 80% of the genome has a "biochemical function". This is a much, much lower bar than my definition used above ("disposable non-coding DNA"). If a stretch of DNA is made into RNA then ENCODE classifies it has having function, even if that RNA transcript has no effect on fitness or phenotype. I have often used the analogy of real trash in your kitchen. Your kitchen trash releases odor molecules into the air in your kitchen which ENCODE would classify as a function since it alters the biochemistry of your kitchen. IOW, ENCODE would classify real trash as not trash. What they have done is define "function" in such a way that it becomes irrelevant. I think sfs has the same opinion, as do most biologists I have talked to. That is why I am accusing ENCODE of salesmanship since they are trying to make their data look more important than it really is.
|
|||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10038 Joined: Member Rating: 5.3
|
Faith,
You seem to have questions about the basics of DNA chemistry, so I thought I would start with the basics of the molecule itself. First, the backbone of DNA is made up of sugars linked together by phosphate groups as seen here:
Notice the numbering on the carbons (those are the carbons that make up the sugar portion of the molecule). The orientation of the carbons, phosphates, and base give DNA a "direction". Enzymes read DNA in what is called the "5' to 3' direction". To use an analogy, the 5' sugar serves as the capital letter at the start of a sentence which allows the reader to read in the correct direction. This is a bit hard to understand, but it is important when trying to figure out how PCR works, and how DNA is replicated. Next, let's focus on the nitrogenous bases. As someone mentioned earlier, bases are complementary. A's match up to T's and G's match up to C's. Why is this? Because of their biochemistry. A's and T's have 2 available hydrogen bonds while G's and C's have 3 available hydrogen bonds. This allows G's and C's to stick together and A's and T's to stick together. You can see how the whole thing lines up here:
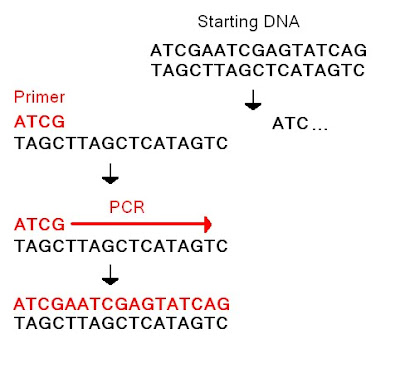
Notice that the strands go in opposite "directions", with 5' to 3' going down on the left side and 5' to 3' going up on the right side. Also notice how the hydrogen bonds line up between the A's and T's and the G's and C's. So with DNA we have two backbones running up each side of the ladder in opposite directions, and the rungs of the ladder are complementary bases that bind to each other through a specific number of hydrogen bonds. All of the technologies we are talking about take advantage of these basic features. PCR uses small chunks of DNA called primers that bind to the complementary bases like a key in a lock. This allows you to target a specific section of DNA. For example:
You will notice that the primer is the complementary sequence to the strand below it. This allows it to specifically bind to that section of DNA. Enzymes then extend the DNA, matching the complementary strand base by base. Once the copying is done you heat the DNA which separates the strands (i.e. "breaks" the hydrogen bonds). This allows the primers to bind to the same spot again and create a new strand. Again, this all happens in the 5' to 3' direction on both strands so you will have copying going on in opposite directions on both strands. Confusing, I know. It takes a while to get these concepts down, but those are the basics. Just to stress this again, the important features are the direction of the backbone (5' to 3') and the complementary nature of the bases (A-T, G-C). Others should feel free to clarifiy or fix any mistakes I have made.
|
|||||||||||||||||||||||||||||||||||||||||||
|
crashfrog Member (Idle past 1488 days) Posts: 19762 From: Silver Spring, MD Joined:
|
I really would like to know about "Junk DNA" and was going to skip to that question anyway when I saw Dr. A's post with the diagram of the Human Genome here: EvC Forum: Flood Geology: A Thread For Portillo It doesn't even mention Junk DNA. Can you explain? I think you've largely got the long and the short of it. "Junk" DNA is a name some people gave to DNA sequences that don't encode proteins. For my own part, I think it's a bad name for a couple of reasons: 1) Even if DNA doesn't encode a protein, it might be involved in regulation, it might be a docking site for structural or regulatory proteins, etc. It may be a "telomere" that allows a cell lineage to know when it's reproduced too many times. 2) Even if it doesn't have any function at all to the organism, it may have once had function, or it might be exogenous to the organism - having been inserted by a virus, it may be a "transposeable element" (transposon), or entered the organism's genome by some other means (like "RNA retrotransposition"). If it did, we should find out if it did, not just write it off as junk. 3) "Bulking out" one's genome with genetic "noise" serves to minimize the effect of frameshift mutations by spreading out the genes. Like most people working in genetics, I generally don't say "junk DNA."
I don't see an indication of what percentage of the Genome is pseudogenes. The human genome? We don't yet know. It's hard to determine whether a gene is actually never expressed, or whether it's merely seldom expressed. Also, our tests have a hard time determining whether a gene is transcribed and expressed, or transcribed but not expressed (this is the fate of some pseudogenes, they appear in the genome and the transcriptome, but not the proteome.) In an organism like a human (or a plant, for that matter) there's an enormous amount of editing in between genetic transcription and building a finished protein, which can make it difficult to look at a gene in the genome and trace it exactly back to a known protein. One paper I just found suggests that the number of pseudogenes in the human genome exceeds the amount of genes. One of the biggest surprised of the human genome project (and the subsequent annotation - actually assigning function to sequence) was how few human genes there are - less than 20,000.
|
|||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10038 Joined: Member Rating: 5.3 |
3) "Bulking out" one's genome with genetic "noise" serves to minimize the effect of frameshift mutations by spreading out the genes.
It also serves as a sponge for external mutagens such as radiation or chemical mutagens. DNA may also serve as actual physical support for the cell, which may explain why the lowly amoeba has a genome that is hundreds of times larger than our own. The concept of junk DNA really comes down to the question you are asking. For a lot of geneticists, they want to know if a sequence is under purifying selection. If it is not, then it is considered junk DNA even if it serves as structural support or as a sponge for mutations. I think this definition fits well in most evo v. creo discussions.
|
|||||||||||||||||||||||||||||||||||||||||||
|
Dr Jack Member  Posts: 3514 From: Immigrant in the land of Deutsch Joined: Member Rating: 8.4 |
3) "Bulking out" one's genome with genetic "noise" serves to minimize the effect of frameshift mutations by spreading out the genes. How does that work then? A frameshift mutation is only a frameshift mutation if it shifts the frame - i.e. if there is a insertion or deletion in the coding region. How will putting them further apart influence that?
|
|||||||||||||||||||||||||||||||||||||||||||
|
crashfrog Member (Idle past 1488 days) Posts: 19762 From: Silver Spring, MD Joined: |
How will putting them further apart influence that? Well, if you pack each gene with introns, and every base has an equal chance of being an indel, then you increase the chance that a frameshift mutation will be canceled out by another one, downstream.
|
|||||||||||||||||||||||||||||||||||||||||||
|
crashfrog Member (Idle past 1488 days) Posts: 19762 From: Silver Spring, MD Joined: |
For a lot of geneticists, they want to know if a sequence is under purifying selection. And by "purifying selection", you mean "natural selection against mutations"?
|
|||||||||||||||||||||||||||||||||||||||||||
|
|
Do Nothing Button
Copyright 2001-2023 by EvC Forum, All Rights Reserved
![]() ™ Version 4.2
™ Version 4.2
Innovative software from Qwixotic © 2024


 (1)
(1)