|

Understanding through Discussion |
|
|
Register | Sign In |
|
QuickSearch
| EvC Forum active members: 64 (9164 total) |
|
| |
| ChatGPT | |
| Total: 916,889 Year: 4,146/9,624 Month: 1,017/974 Week: 344/286 Day: 65/40 Hour: 1/5 |
| Thread ▼ Details |
|
Thread Info
|
|
|
| Author | Topic: Genetic and Cellular Mechanisms and Variation | |||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days)  Posts: 1517 From: Michigan Joined:
|
I am proposing this thread to focus on basic genetic and cellular mechanisms and how they produce variation. The emphasis will be on molecular processes rather than population systems and as such will not, for the most part, deal with common evolutionary subjects such as genetic drift, natural selection and the fossil record. Furthermore, unless otherwise specified, discussion will center on eukaryotic cell biology rather than prokaryotic, since I suspect more people are interested in the evolutionary processes of metazoans than they are of bacteria.
This is a substantial subject and I don’t expect to get through this material quickly. My goal will be to make at least one significant post every week unless there is significant discussion regarding a previous post. As I thought about how to begin this series, I decided I would start with the assumption that most people have an elementary knowledge of genetics, such as the structure of DNA, so I am going to skip the most rudimentary topics. As for my credentials, I am not a professional as such yet. I have a B.A. in Environmental Biology and am anxiously awaiting my acceptance letter from MSU into their Plant Pathology program. I did very well in both my undergrad Genetics and Cell Biology courses (both taught by the most difficult professor in the NS department). I am currently teaching a Microbiology lab and a Human Physiology lab as an adjunct instructor. My primary reference source will be Lodish, et. al. (2013). Molecular Cell Biology 7th edition, W.H. Freeman and Co. Any material that should be referenced will be considered to have come from this source. Material from other sources will be referenced appropriately. Credits for images can be found by using the peek button unless otherwise noted. While questions, comments and even discussions about the topics being covered are certainly welcome, I would like this thread to be primarily informational (I am reluctant to call it a course though) and would ask that debates, especially regarding EvC issues be addressed in separate threads. Biological Evolution, please. HBDWhoever calls me ignorant shares my own opinion. Sorrowfully and tacitly I recognize my ignorance, when I consider how much I lack of what my mind in its craving for knowledge is sighing for... I console myself with the consideration that this belongs to our common nature. - Francesco Petrarca "Nothing is easier than to persuade people who want to be persuaded and already believe." - another Petrarca gem. Ignorance is a most formidable opponent rivaled only by arrogance; but when the two join forces, one is all but invincible.
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined:
|
Chromosome refers to the basic organizational structure which eukaryotic cells package their DNA. Although how the chromosome is arranged does have an effect on gene expression and regulation, there is nothing particularly special about how the DNA is packaged that relates to organismal complexity or size.
More specifically, the term chromosome refers to the highly condensed structures that are visible with a light microscope during cell division. In non-dividing cells, the DNA is more diffuse and spread throughout the nucleus. If the DNA strands in a human cell were stretched out end to end, they would be about 1.2 meters long! Obviously, the cell needs a way to package these long strands in order to fit them within the confines of a cell. It also needs to package it in such a way as to be readily accessible for transcription, replication, and repair, to prevent tangling and knotting, and to preserve integrity during cell division.
The first step is to form nucleosomes in which the DNA strand is wrapped around a complex of histone proteins. This structure has the appearance of beads on a string with nucleosomes separated by free DNA called linker DNA. Nucleosomes consist of about 150 bp of DNA wrapped around the histone complex about one and two-thirds times. The length of the linker DNA varies from 10 to 90 bp depending on the organism and cell type. This complex of histones and DNA is referred to as chromatin and is the primary organizational structure of genes undergoing active transcription. Remarkably, the general structure of chromatin is highly similar in the cells of all eukaryotes, including plants, animals and fungi. The amino acid sequences of the histone proteins are highly conserved, even between distantly related species. For example, the histone H3 varies by only one amino acid between the sea urchin and calf thymus and the H3 histone from the garden pea differs from calf thymus by only four amino acids. The chromatin in regions that are not undergoing active transcription or replication form a structure know as a 30nm fiber. In this structure, another histone protein (H1) associates with the nucleosomes and wraps the strands of nucleosomes into a tight, left-handed double helix with the nucleosomes stacking on top of each other. The folding of eukaryotic chromatin during cell division is not well understood, but generally the 30nm fiber loops into a 300nm loop domain and again loops into the 700nm fiber of the metaphase chromatid.
Source: DNA Learning Center
Only about 1.5% of human DNA encodes functional proteins or RNA molecules. The remainder is mostly spacer DNA between genes and introns within genes. Below is a brief description of the major type of DNA sequences. Major types of DNA sequences ------------------------------------------------------------------------ Single-copy genes Gene families Tandemly repeated genes Introns Simple-sequence DNA Transposable DNA elements Spacer DNA (Lodish, p. 224)
Genes are the primary unit of inheritance. It is common to think of a gene as a segment of DNA that encodes a protein, but genes actually include much more than simple protein coding sequences. A gene is the entire nucleic acid sequence that is necessary for the synthesis of a functional gene product, which could be a polypeptide or an RNA molecule. Therefore, a gene includes all of the DNA sequences of the introns, exons, promoters, enhancers, and transcription-control factors associated with that gene product. Single-copy genes appear only once within the genome.
Gene families are a set of genes that appear to have arisen by duplication and have subsequently diverged due to small changes in nucleotide sequences.
Tandemly repeated genes are multiple copies of identical or nearly identical genes most often occurring one after the other in a head-to-tail fashion. These multiple copies are needed to meet the high demand of some gene products.
Introns are part of the primary transcription unit but are spliced out during mRNA processing and not included in the mature mRNA product. Most introns are broken down and recycled but some are known to form usable RNA products.
Simple-sequence DNA, also called satellite DNA, is short, tandemly repeated sequences that are found at centromeres and telomeres as well as at other locations that are not transcribed.
Transposable DNA element is a DNA sequence that is not present in the same chromosome position of all members of a species, but can move to a new position by a cut-n-paste method. Also called a mobile DNA element or interspersed repeat. You may have heard this referred to as a "jumping gene."
Spacer DNA is unclassified DNA sequences that lie between transcription units. It also is found in transcription-control regions and helps regulate transcription from distant promoters or enhancers. Some spacer sequences are highly conserved indicating they may have a significant function, such as contributing to the structural organization of chromosomes. Roughly 25% of human DNA is in this category of unclassified spacers. This post provides a basic overview of how eukaryotic chromosomes are organized. We will discuss these various types of DNA sequences, how mutations can accumulate in them and how we can use those mutations for identification as this thread progresses. HBD
|
|||||||||||||||||||||||||||||||||||||||
|
Admin Director  Posts: 13040 From: EvC Forum Joined: Member Rating: 2.2 |
Thread copied here from the Genetic and Cellular Mechanisms and Variation thread in the Proposed New Topics forum.
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined:
|
Gene Structure and Transcription
This post will deal with general gene structure and the basics of how the cell regulates gene expression.
The above image illustrates the key elements of a typical eukaryotic gene. Transcription begins at the transcription start site and proceeds in the direction of the red arrow stopping at the termination site. This transcribed region will become pre-mRNA which includes introns, exons, a 5’ (read: "five prime") untranslated region (UTR) and a 3’ UTR. The initiator (start) codon and the terminator (stop) codon mark the limits of the protein coding sequence.
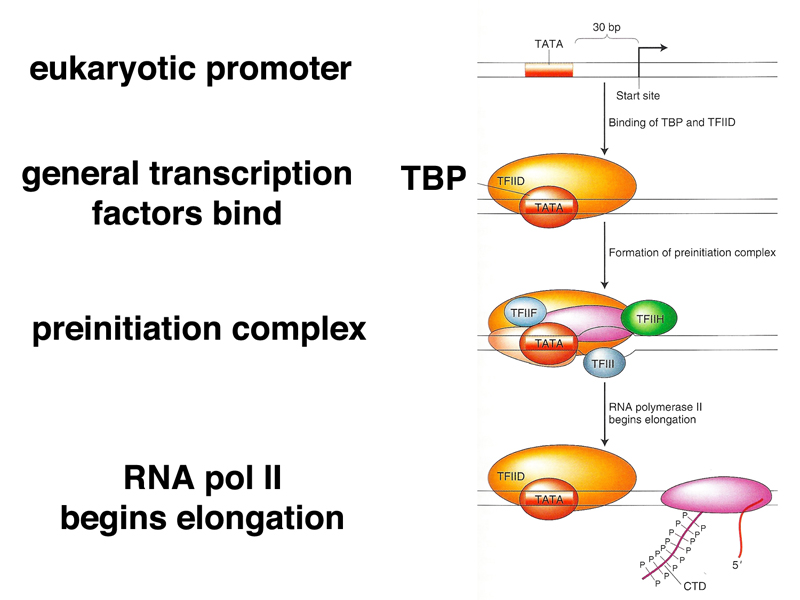
Pre-Initiation Complex Upstream (the opposite direction of transcription) of the transcription start site there is a promoter region and an upstream regulatory region (also known as an enhancer). There are several types of eukaryotic promoters, but one of the more common and well-studied is the TATA box. Before transcription can begin, general transcription factors must bind to the promoter region. The first transcription factor to be recruited is called TBF or TATA binding factor, which binds directly to the TATA box. TBF then recruits a series of other transcription factors to the site. These transcription factors are necessary for the recruitment of RNA polymerase II.
Promoter Region The promoter region serves a couple of purposes. First it serves to position the RNA polymerase at the correct location for the start of transcription, which begins about 25 bp downstream from the TATA box. Deletions or insertions in this region will shift the transcription start point and lengthen or shorten the pre-mRNA. Small shifts in this region are unlikely to affect the final polypeptide as the start and stop codons will be unaffected; it will be the length of the 5’ UTR that will be affected. The second function of the promoter region is to regulate gene expression. This process of forming an initiation complex is the most frequently regulated step in determining when and in which cells specific proteins are expressed. Inhibitors can attach to the promoter region and prevent transcription factor recruitment, or other transcription factors can be inactivated by a cell signal or remain inactive until activated by a cell signal. There are roughly 2000 different transcription factors encoded in the human genome and different combinations of these factors allow expression of cell-type specific gene expression. These controls and the importance to variation will be discussed in more detail at a later time.
Initiation Protein complexes known as activators bind to the upstream regulatory regions. When everything is in place, the activators make contact with the initiation complex and release RNA polymerase II which begins transcribing the mRNA molecule.
Elongation Recent work has shown that in metazoans, for most promoters, RNA Pol II pauses after transcribing about 20 - 50 nucleotides due to a protein complex known as NELF (negative elongation factor). Pol II remains stalled until this elongation inhibitory complex is phosphorylated, releasing Pol II to continue transcription. This mechanism provides an additional level of regulatory control over gene expression. The RNA polymerase proceeds down the DNA template strand in a 3’ to 5’ direction copying the DNA strand into an mRNA strand. RNA is very similar to DNA with a couple of significant differences. RNA uses the 5 carbon sugar ribose rather than deoxyribose of DNA and rather than the nucleotide bases C (cytosine), G (guanine), A (adenine), and T (thymine) of DNA, RNA uses the bases G, C, A, and U (uracil).
As the polymerase proceeds, the double stranded DNA coil is unwound and NTPs (nucleoside triphosphate) enter through an intake hole. Just as with DNA, nucleotides can only be added to the 3’ end of the growing RNA strand, which constrains which strand will act as the template. The nucleotides are added one base at a time by pairing each DNA base with its complimentary RNA base; C is paired with G and A is paired with T / U. The RNA strand exits the polymerase and the DNA strand is rewound.
Termination When the RNA polymerase II reaches the transcription termination site, the polymerase releases the pre-mRNA and disassociates from the DNA. The polymerase is then free to transcribe the same gene or a different one. Termination is not that well understood in eukaryotes and the explanation is rather involved. So, since it is not really important to this discussion I will skip the mechanistic explanation of termination.
Regulation of Transcription There are several variations on the theme of transcription regulation. However, transcription activators and repressors work largely by binding to co-activators or co-repressors that influence the assembly of the initiation complex. Changes in the affinity that the different transcription factors have for one another will affect the likelihood that a functional initiation complex will be assembled. In other words, when the affinity is high, the components will be recruited rapidly and transcription will be high. When the affinity is low, recruitment will be slow and transcription will be reduced. To illustrate the complexity of these transcriptional signalling pathways, the illustration below is the transcriptional control pathway for a protein called TGF-beta (Transforming growth factor beta). Note the multiple levels at which each regulatory component is controlled.
Enhancers generally range in length from 50 to 200 bp and can be bound by several transcription factors or a large complex of factors. Because the region between promoters and enhancers is flexible and there is considerable leeway in the spacing between control elements, there are considerable variations in the functional combinations that can exist. There can even be multiple enhancers that can operate cooperatively depending on cell-type and expression levels required. Another way cells control gene expression is by modification of chromatin structure. DNA that is in highly condensed regions of chromatin is relatively inaccessible to transcription factors and gene expression is repressed. Proteins that acetylate or deacetylate histone tails play a large role in chromatin-mediated gene expression. Deacetlyated histones have charged tails that can interact with each other and are more likely to fold into condensed, higher-ordered structures. Acetlyated histones have tails that are bound by an acetyl group and so are less likely to interact with each other, therefore the structure is more open and accessible to transcription factors. As you can see, the cell has multiple levels of control over transcription and utilizes them to precisely regulate gene products. The cell can not only turn genes on and off using these transcription controls, but can also control levels of gene products and the timing at which they are produced. This control over gene expression is what makes cell differentiation possible and allows multi-cellular life to exist. It is commonly thought that the primary way to produce novel functions or structures is by altering gene sequence and thus the subsequent protein structure. However, every cell in an organism (with a few exceptions) has the same genetic code and yet that same genetic code can produce 100’s of different cell types and functions. The primary way the cell does this is by regulating transcription. Therefore, mutations that affect transcriptional patterns can result in novel cell types or functions even without changing protein sequences. We will be expanding on this idea somewhat as this thread progresses, although it goes a bit to far into developmental biology for this thread or my knowledge level. HBD Edited by herebedragons, : Added Title
|
|||||||||||||||||||||||||||||||||||||||
Faith  Suspended Member (Idle past 1472 days)  Posts: 35298 From: Nevada, USA Joined: |
I love the animations, already watched the one in this post at You Tube many times before you posted it. (and it does inspire me to say that it's absurd to believe all this amazingly complex organization and in fact orchestration occurred randomly by chemical processes just happening to come together over billions of years but that's another subject of course)
But this material is way way too complex for me, I don't know about others here. At least it's too much to try to digest from one post. Perhaps it should be broken down into bite--sized pieces, not sure. Edited by Faith, : No reason given. Edited by Faith, : No reason given.
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined: |
I love the animations, Yea, the DNA learning Center has some great resources.
and it does inspire me to say that it's absurd to believe all this amazingly complex organization and in fact orchestration occurred randomly by chemical processes just happening to come together over billions of years but that's another subject of course Definitely a different subject.
But this material is way way too complex for me, I don't know about others here. Yes, it is complex. But if you're going to say things like:
quote: Then you need to either understand why we think that mutations can and DO such things or be able to point to specific reasons why they can't - not just made up probabilities. That is simply the argument from incredulity ... "I cant understand it so it must not be right."
At least it's too much to try to digest from one post. Perhaps it should be broken down into bite--sized pieces, not sure. Take it slow. I am not going to be able to post every day ... about once a week is the goal. I have broken it down into sections with headings - to put them in separate posts wouldn't help, it would just make lots of posts. So far, I have only discussed the most basic mechanisms. I have been worried it is too simplistic and most people would find it boring and mundane. But I have to establish these basic processes so that when I discuss the mechanisms that generate mutations and how we use those known mechanisms for DNA fingerprinting, inferring genetic relationships and how mutations can produce novel features they have some context. Do you get the point that transcriptional control is the major process that leads to cellular differentiation? If not, feel free to ask questions. HBDWhoever calls me ignorant shares my own opinion. Sorrowfully and tacitly I recognize my ignorance, when I consider how much I lack of what my mind in its craving for knowledge is sighing for... I console myself with the consideration that this belongs to our common nature. - Francesco Petrarca "Nothing is easier than to persuade people who want to be persuaded and already believe." - another Petrarca gem. Ignorance is a most formidable opponent rivaled only by arrogance; but when the two join forces, one is all but invincible.
|
|||||||||||||||||||||||||||||||||||||||
|
Faith Suspended Member (Idle past 1472 days) Posts: 35298 From: Nevada, USA Joined: |
If your objective is to teach me about why you all believe in mutations, I'm not sure this is the best way to accomplish that.
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined:
|
If your objective is to teach me about why you all believe in mutations First, I don't "believe" in mutations anymore than I "believe" that my body is made up entirely of individual cells. Mutations are a fact of biological systems. They introduce variation and provide the organism with novel responses to environmental pressures. Second, while my discussions with you did inspire me to start this thread, I am not doing it specifically for you.
I'm not sure this is the best way to accomplish that. Maybe not. But the real story about mutations is what happens at a molecular level. To view it from only a macro-level perspective, it can seem mystical. That's why creationists say things like "mutations can't provide new information" or they think that mutations must "pop up at just the right time" to provide a benefit. And "genetic similarity does not indicate genetic relatedness." All these ideas come from a general ignorance of the underlying mechanisms and consequences of mutations. So maybe you are resistant to learning about this, but maybe someone else can get a benefit from it. Its not a "I want to teach Faith a thing or two" thread, because I realize your mind is already made up. HBDWhoever calls me ignorant shares my own opinion. Sorrowfully and tacitly I recognize my ignorance, when I consider how much I lack of what my mind in its craving for knowledge is sighing for... I console myself with the consideration that this belongs to our common nature. - Francesco Petrarca "Nothing is easier than to persuade people who want to be persuaded and already believe." - another Petrarca gem. Ignorance is a most formidable opponent rivaled only by arrogance; but when the two join forces, one is all but invincible.
|
|||||||||||||||||||||||||||||||||||||||
|
NoNukes Inactive Member
|
I have broken it down into sections with headings - to put them in separate posts wouldn't help, it would just make lots of posts. Just to provide another data point for you. What I saw was a video about transcription included in a post that explained every important term in the video that I was unfamiliar with. And as an electrical engineer/physics/programmer type, terms I was unfamiliar with' means essentially all of them except DNA and RNA. I found the presentation so far to be quite accessible without undue effort. Under a government which imprisons any unjustly, the true place for a just man is also in prison. Thoreau: Civil Disobedience (1846) I have never met a man so ignorant that I couldn't learn something from him. Galileo Galilei If there is no struggle, there is no progress. Those who profess to favor freedom, and deprecate agitation, are men who want crops without plowing up the ground, they want rain without thunder and lightning. Frederick Douglass
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined: |
I found the presentation so far to be quite accessible without undue effort. Thank You. It can be difficult to strip off all the extra details and focus on just what is important and yet still not make it too simplistic that it's boring. HBDWhoever calls me ignorant shares my own opinion. Sorrowfully and tacitly I recognize my ignorance, when I consider how much I lack of what my mind in its craving for knowledge is sighing for... I console myself with the consideration that this belongs to our common nature. - Francesco Petrarca "Nothing is easier than to persuade people who want to be persuaded and already believe." - another Petrarca gem. Ignorance is a most formidable opponent rivaled only by arrogance; but when the two join forces, one is all but invincible.
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined: |
mRNA Processing
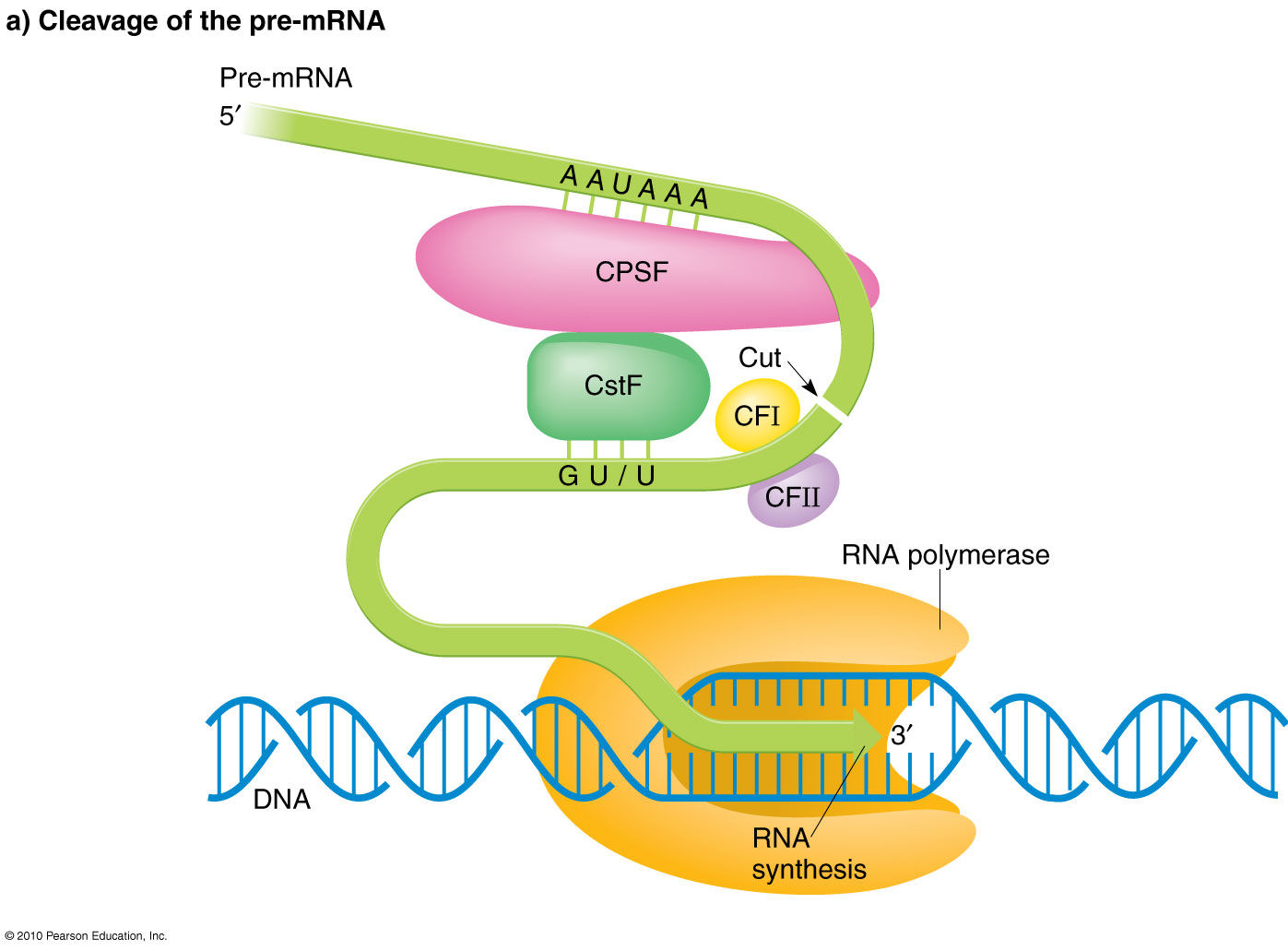
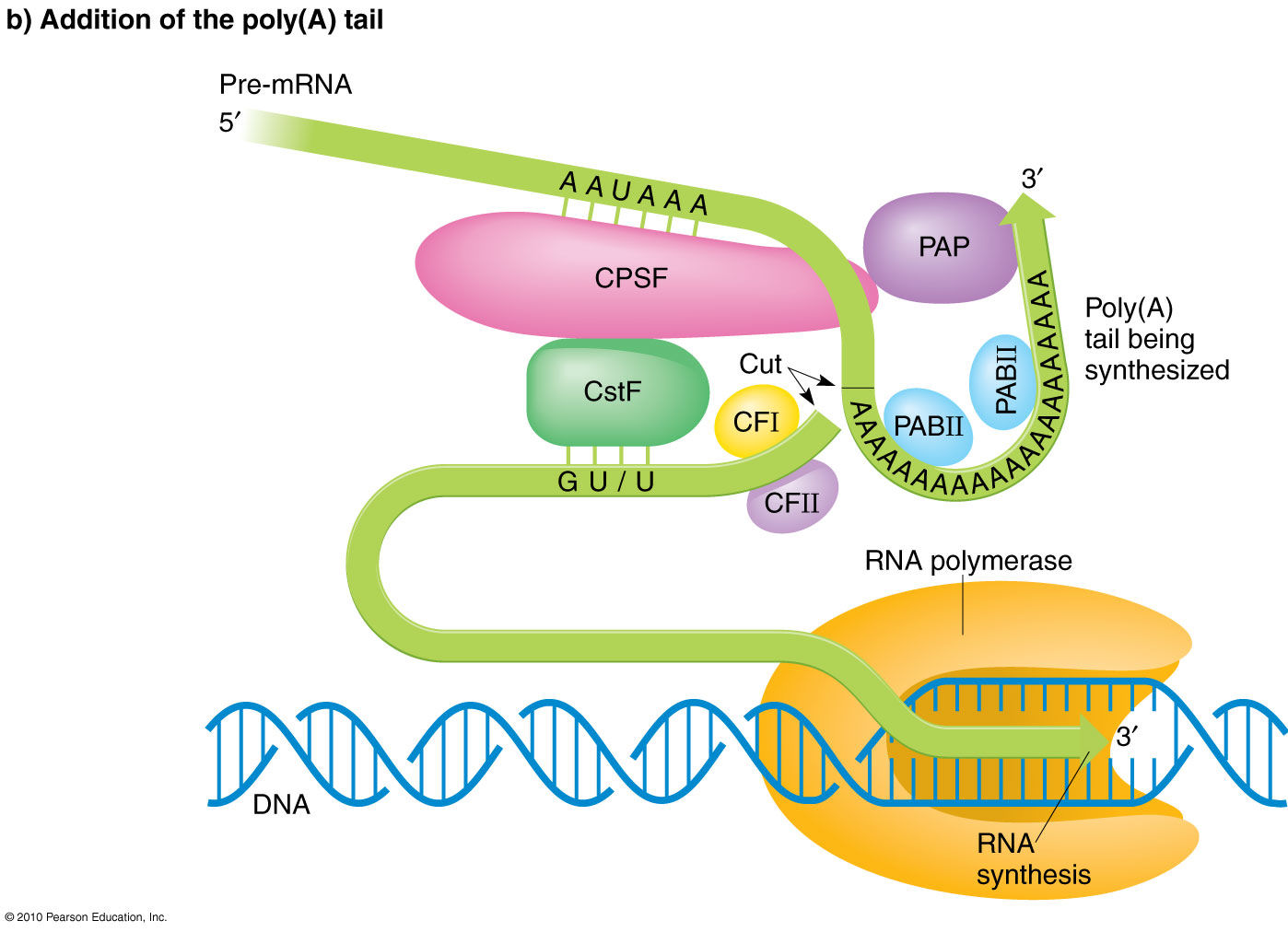
Prokaryotic cells, such as bacteria, do not have a nuclear envelope and the transcribed mRNA can immediately be translated into protein. In fact, transcription and translation often occur simultaneously with multiple ribosomes working on the same mRNA as it is still being transcribed. Eukaryotic mRNA however, must undergo extensive processing and be exported from the nucleus before it can be translated into protein. First, the 5’ end is capped and the 3’ end is modified with a poly(A) tail. These modifications provide protection for the mRNA from hungry nucleases that would degrade the RNA strands quite rapidly. The introns are then spliced out and the exons are spliced together. The mature mRNA is then labeled for export with special proteins and shuttled out of the nucleus, ready to be translated into protein. This post will deal with post-translational mRNA processing. The image below is an overview of the process.
5’ methylated cap Shortly after transcription begins, the leading end (5’ end) is capped with a modified guanylate nucleoside, also called 7-methylguanylate or m7Gpp(pN). Rather than a typical 5’ --> 3’ nucleotide bond, the 5’ cap binds through a phosphate bridge of 2 additional phosphates, into a 5’ --> 5’ configuration. This makes the cap highly resistant to degradation by nucleases.
3’ poly(A) tail After transcription termination, cleavage and polyadenylation specificity factors (CPSF) bind to a poly(A) signal sequence, typically AAUAAA, and another protein complex, CStF, interacts with a downstream G/U signal. Binding complexes, CFI and CFII, help stabilize the assembly and form a loop in the RNA. Poly(A) polymerase (PAP) then binds and stimulates cleavage at the poly(A) site. CStF, CFI and CFII release and PAP adds a string of 200 -250 adenine residues to the 3’ end.
The purpose of both the 5’ cap and the 3’ poly(A) tail is to protect the newly synthesized mRNA from degradation by exonucleases.
Intron Excision Introns are the portion of the primary transcript that is removed during RNA processing and not included in mature mRNA. It is non-coding.
Exons are the portion of the primary transcript that is retained in mature mRNA and is translated into a protein in the cytoplasm. Exons are the coding segments of pre-mRNA. A typical human gene is on the order of 50,000 bp long. However, about 95% of that sequence is introns and non-coding UTRs (untranslated regions). The average intron length in human genes is 3.3 kbp, while exons are a mere 50 - 200 bp. In order to produce a functional mRNA, these introns must be cut out and the exons spliced together.
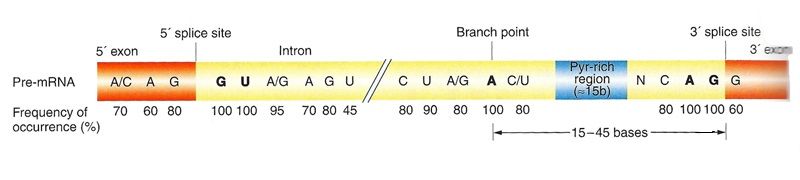
The figure above is an estimate of the consensus sequences surrounding splice sites based on vertebrate intron sequences. Note the G U bases at the 5’ end of the intron, the A G bases at the 3’ end and an A at the branch point are 100% conserved in vertebrate genes. Also notice a pyrimidine rich region, where pyrimidines occur in these 10 - 15 bases greater than 80% of the time. These regions are important for the assembly of the splicing mechanism known as the spliceosome. Note: remember that pyrimidines are the single aromatic ring bases cytosine, thymine (DNA) and uracil (RNA), while purines are the double aromatic ring bases guanine and adenine - pyrimidines pair with their complementary purine ie. C:G and A:T/U The spliceosome is made up of 5 snRNA (small nuclear RNAs) and approximately 170 associated proteins. snRNAs are a group of small, stable RNA molecules that are localized in the nucleus. The 5 snRNAs that make up the spliceosome are between 107 and 220 bp in length and are U-rich (meaning they have a predominance of the base uracil). Each of these snRNAs associate with 6 - 10 proteins in a complex called a small nuclear ribonucleoprotein particle or snRNP (pronounced: snerp). To remove the intron and splice the exons together, the snRNPs bind to the 5’ end G - U sequence and the 3’ end A - G sequence. The 5’ end is then pulled towards the branch point, a splice is made at the 5’ splice site and a phosphate bond is made between the G and the A of the branch point. A splice is then made at the 3’ splice site and the intron is freed from the spliceosome. A phosphate bond is then formed between the 3’ end of one exon and the 5’ end of the other, thus reforming a continuous strand of mRNA. The free intron, which has formed a lariat structure, is then degraded and the nucleotides are recycled. DNA Learning Center RNA splicing video
So why would the cell expend so much energy producing introns that are only to be cut out and recycled? The first reason is that we find mutations are an inevitable part of biological systems. Not only are there mistakes made during replication, but there is also damage from UV radiation, chemical mutagens, etc. Having such large sections of non-coding DNA significantly lowers the probability that a mutation will occur in a region that may reduce or impair functionality. The second reason is that it gives the cell options as to how to splice that mRNA back together. This is referred to as alternate splicing and allows the cell to produce varied gene products with the same set of genes.
Complex Transcription Units Eukayotic genes can be divided into two categories; simple transcription units and complex transcription units. Simple transcription units are those that encode a single protein. Complex transcription units produce a primary transcript product that can be processed in alternate ways. Regulation of RNA splicing is an important part of gene expression in higher eukaryotes. The image below shows several examples of how a gene can be alternately processed.
The cell can select different splice sites by producing splicing repressor proteins or splicing activator proteins that bind to alternate splicing sites and therefore, direct the spliceosomes to different splicing sites or block a site altogether. In example (f), selection of alternate promoters leads to the production of different gene products. Example (g) shows what happens when a gene has multiple poly(A) sites. If the blue exon is not spliced out, the mRNA will be clipped at that poly(A) site even though the pre-mRNA is transcribed beyond the third exon.
Transport across Nuclear Membrane The nuclear membrane is highly regulated as to macromolecules that are allowed to pass through. In order for macromolecules, such as mRNA, to be transported to the cytoplasm for translation, they must pass through nuclear pore complexes (NPCs). NPCs are large, symmetrical structures that are imbedded in the nuclear membrane. Nuclear export factors, nuclear export transporter proteins and other adaptor proteins form associations with the mature mRNA and provide the necessary interaction with the NPCs to allow export into the cytoplasm. These export proteins then disassociate with the mRNA and are recycled back into the nucleus for reuse. Once the mRNA enters the cytoplasm, it is ready for translation into a protein. We will cover this process next. HBD Edited by Admin, : Rerender for mobile usability.
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined: |
Alternative Splicing in Drosophila Sex Determination
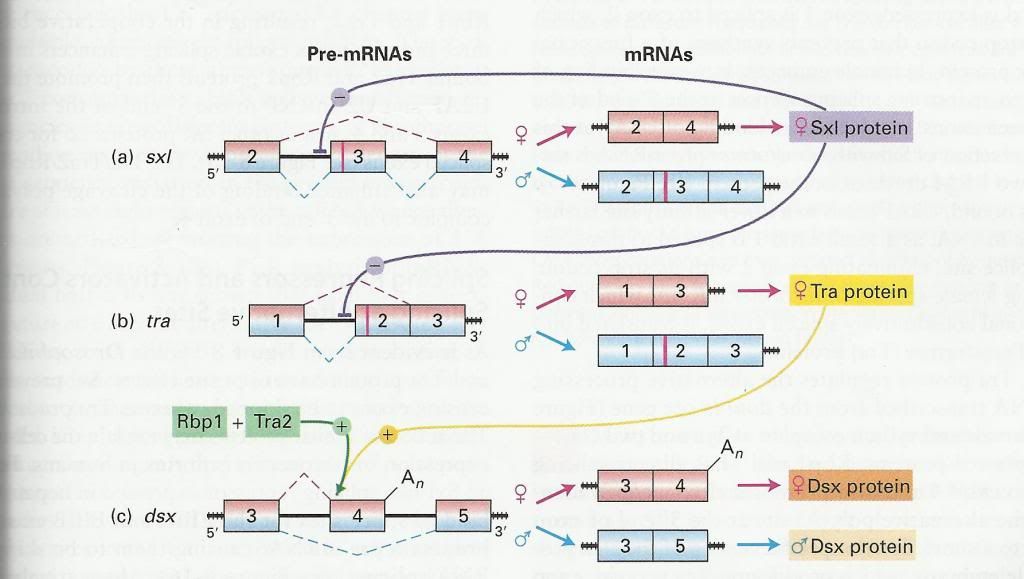
In this post, I present an example of regulated alternate splicing of pre-mRNA. This example comes from the sex differential pathway in Drosophila and involves a cascade of splicing inhibitors and activators. The diagram below illustrates this pathway. Only exons and introns where regulated splicing occurs are shown. Scrunched black lines at the ends indicate mRNA extends further in that direction.
Early in development, the sex-lethal gene (Sxl) is transcribed from a promoter that is only active in females and is translated into early Sxl protein (not shown on diagram above). Male flies do not have access to this female specific promoter and so do not produce this early Sxl protein. Later in development, this female specific promoter is turned off and another, non-specific promoter is activated (fig a) and both male and female flies begin transcribing the Sxl gene. The presence of early Sxl protein acts as a splicing inhibitor at the 5’ splice site of exon 3 by blocking the proper association of U2 and U2AF. This causes the U1 snRNP assembled at the 3’ splice site of exon 2 to associate with the spliceosome assembling between exon 3 and 4 and thus skipping exon 3. This produces late Sxl protein which continues to act as a splicing inhibitor on the Sxl gene and reinforces its own expression. Since male flies do not produce early Sxl, the protein produced from the Sxl gene includes exon 3, which contains a stop codon (red vertical line). This produces a truncated, non-functioning Sxl protein. The result is that male embryos produce neither early or late Sxl protein. The Sxl protein also regulates transcription of the transformer gene (Tra) by again acting as a splicing inhibitor and skipping exon 2, which produces a functional Tra protein in females (fig b). Male transcription of the Tra gene produces an mRNA that includes exon 2 and its stop codon and again, produces a non-functional protein. The Tra protein regulates the alternate processing of double-sex (Dsx) gene pre-mRNA (fig c). However, in this case Tra, in association with two other proteins, Tra2 and Rbp1, acts as a splicing activator and directs splicing to the 3’ end of exon 4. Exon 4 contains an alternate poly(A) site and is clipped off near the end of exon 4 and a short, female specific version of the Dsx protein is produced. Males produce no Tra protein, so exon 4 is skipped and a longer, male specific version of the Dsx protein is produced. This cascade of alternate splicing activity results in the expression of male and female specific sex determination genes. Dsx protein is a transcription repressor and male Dsx will inhibit the expression of genes required for female development and female Dsx will inhibit the expression of genes required for male development.
Expression of K+-Channel Protein in Vertebrates Another remarkable example of alternate splicing is found in the inner ear of vertebrates. The cells in the inner ear are ciliated neurons, or inner hair cells, which respond to specific frequencies of sound. Cells are individually tuned, with those tuned for low frequency at the apical end of the cochlea and those tuned for higher frequencies located at the basal end. The cells in between these two extremes are tuned to a gradient of frequencies. One of the components involved in tuning these auditor sensors is a K+ ion channel that opens in response to intercellular Ca2+ concentrations. The frequency at which the cell is tuned is determined by the Ca2+ concentration at which the K+ channel opens. Note: Neurons function by creating a voltage potential which is used to release a neurotransmitter which is then transmitted to the brain and processed as stimuli. This voltage potential results from pumping ions in and out of the cell. The gene that encodes this ion channel is expressed as multiple, alternately spliced isoforms. In fact, there are 8 regions where alternate splicing occurs, permitting the expression of up to 576 different isoforms of the protein. Hair cells with different frequency response express different isoforms of this ion channel, with different forms predominating depending on their position along the cochlea. It is not difficult to imagine how mutations could affect this system. If a mutation occurred that caused more high frequency isoforms to predominate, the ear would become more sensitive to high frequency sounds. Likewise if low frequency cells became dominant, the ear would be more sensitive to low frequency sounds. Also, splice site could be altered; eliminating some of the options or potentially creating new ones and extending the frequency response range either up or down. It should be clear that alternate splicing is a tremendously valuable tool available to the cell and has the potential to produce considerable variation. HBD Edited by herebedragons, : No reason given.
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined:
|
Not sure if anyone is reading this, but it gets pushed down to the bottom of the stack rather quickly since I don't post everyday. I just thought I would give it a bump in case anyone missed it that was interested.
HBDWhoever calls me ignorant shares my own opinion. Sorrowfully and tacitly I recognize my ignorance, when I consider how much I lack of what my mind in its craving for knowledge is sighing for... I console myself with the consideration that this belongs to our common nature. - Francesco Petrarca "Nothing is easier than to persuade people who want to be persuaded and already believe." - another Petrarca gem. Ignorance is a most formidable opponent rivaled only by arrogance; but when the two join forces, one is all but invincible. |
|||||||||||||||||||||||||||||||||||||||
|
Taq Member  Posts: 10084 Joined: Member Rating: 5.1 |
HBD, you are doing a great job. You obviously have ideas mapped out over multiple posts, so I have not felt the need to jump in and add new material. What material you have presented is well written and understandable, but I may be a poor judge for this since I already understand the subject.
Keep it going . . .
|
|||||||||||||||||||||||||||||||||||||||
|
herebedragons Member (Idle past 885 days) Posts: 1517 From: Michigan Joined: |
Translation
After the mature mRNA leaves the nucleus it is ready to be translated into a polypeptide, otherwise known as a protein. Translation is the process by which the sequence of an mRNA is converted into the appropriate polypeptide by assembling amino acids in a specified order. This is accomplished by three major types of RNA: messenger RNA (mRNA), transfer RNA (tRNA) and ribosomal RNA (rRNA). This post will describe the process of translation and how these three types of RNA function to produce proteins. The video below provides a good overview of the translation process:
Genetic Code The genetic code used by cells is a triplet code consisting of a three nucleotide sequence called a codon. These codes are read from a starting point on the mRNA strand and continue until they reach the ending point. This starting point is called the start codon and the end point is called the stop codon. The sequence of codons that runs between the start codon and the stop codon is known as the reading frame. The order of codons in the reading frame determines the arrangement of amino acids in the synthesized polypeptide. The meaning of each codon sequence is the same in almost all organisms, which is considered to be a strong argument that life arose only once in the history of the earth and that all organisms share a common ancestor. In fact, the genetic code is so consistent that it is known as the universal code. Of course, as one would expect with living organisms, there are a few known exceptions to the universal code found in some mitochondria and protozoans. Another feature of the universal code is that it is degenerate, meaning that a particular amino acid is coded by several different codon sequences. Since there is 64 different possible codons and only 20 amino acids, most amino acids have multiple codons that can specify it. The different codes for a single amino acid are said to be synonymous. The table below shows how to interpret the codon sequences and indicates the amino acid that is specified by each codon.
Note: the line above the codon AUA was inappropriately placed. The codon AUA codes for Ile (Isoleucine) and should be grouped with the two codons above it. To use the table, the first letter of the codon is read from the left side and determines the row running across the table. The second letter is read from the top column and determines the column. The third letter of the codon is read from the right side of the table and determines the sub-row. As an example, the codon AUG would indicate the amino acid methionine (Met), which is a start codon. Three of the codons do not code for an amino acid but indicate the stop codons.
Transfer RNA The key to translating the code and assembling the correct amino acid is the transfer RNA or tRNA. The tRNA binds an amino acid and carries it to end of the growing protein chain where it is attached when called for by the mRNA. The tRNA recognizes the proper codon because each specific tRNA has a three nucleotide sequence that binds to the complementary codon sequence. Remember that in RNA, adenine (A) pairs with uracil (U) and guanine (G) pairs with cysteine (C). So, the tRNA that carries methionine would have an anti-codon sequence of UAC, which is complementary to the mRNA codon AUG. The image below shows this codon / anti-codon pair and also the amino acid attachment site.
Now, before any of you get excited and think Wow tRNA looks a lot like a cross, that must be significant, the image on the right is the 3 dimensional structure, which looks absolutely nothing like a cross. However, it does bring up an important characteristic of RNA that I will discuss briefly. Because RNA is single stranded, it tends to form stem and loop structures. In the 2D drawing of the tRNA, you should notice that there are several base pairings, particularly G -C pairings, which form a stem-like structure. Those bases that remain unpaired form loop structures. These structures are important in the stabilization, function and regulation of RNA. You also may notice on the 2D drawing that there are several non-standard bases included in the tRNA strand. These are nucleotide bases that are modified post-transcriptionally but are not really important to this discussion, so I am not going to go into that much detail. They are involved in the recognition and association of the proper amino acid to the particular tRNA. If you would like, you can test yourself to see if you understand how the universal code works by translating the following sequence into an amino acid sequence. (hint: remember to look for start and stop sequences). Answer at the end of this post. 5’ - C G A U G C U C A A U C G G U A C A A G C A U G G A C C A U G G U A A C U A G - 3’ Now mutate the 3rd base from the 5’ end from an A to a T and determine the protein sequence.
Ribosomes Ribosomes are the protein assembly machinery that reads the mRNA, locate the tRNA in the appropriate position, catalyzes the amino acid attachment to the polypeptide and shifts the mRNA to the next codon in the sequence. An assembled ribosome consists of two subunits; a small subunit and a large subunit. Both subunits are composed of ribosomal RNA (rRNA) and some associated proteins. Ribosomes are generally free-floating in the cytosol (the liquid in the cell that is outside of the nucleus) and assemble onto the mRNA in this free-floating state. However, if you were to characterize ribosomal activity you would find that it is concentrated in the area of the endoplasmic reticulum (ER), which is essentially a cytoplasmic extension of the nuclear membrane. When a protein that is targeted for excretion, for insertion into the cell membrane, or for incorporation into certain organelles is translated, the ribosome associates with the ER membrane. Protein trafficking is not something I have time to cover in this post (it will require an entire post of its own) but I hope to be able to cover it at a later time because it is an important feature of the cell than can be affected by mutational changes and can provide novel protein function.
Translation, Initiation The main objective of this post is to explain how the ribosome translates the mRNA into a protein. First, a preinitiation complex forms between a small ribosomal subunit, a specially modified methionine initiation tRNA (Met-tRNAimet) and some additional proteins. Then the small subunit attaches to the mRNA and theMet- tRNAimet positions the ribosome at the start codon. (Keep in mind that I am stripping off some of the details of this process there is also an association with the poly(A) tail and some additional translation factors).
Translation, Enlongation
Once the initiation complex is in place, the large ribosomal subunit assembles onto the small subunit and the initiation proteins disassociate. The ribosome is now ready to begin translation. The ribosomal machine consists of three positions; the A-site (aminoacylated tRNA binding site), the P-site (polypeptide attachment site) and the E-site (ejection site). Various tRNAs enter the A-site until an appropriate match between the codon in the A-site and the anticodon of the tRNA is found. If an unmatched tRNA enters, it cannot form a proper bond and is ejected from the ribosome, leaving an empty site for another tRNA to enter. Once a suitable match is made, a tight bond is made between the tRNA anticodon and the codon of the mRNA. A peptide bond is then formed between the amino acid in the P-site and the amino acid in the A-site with the string of amino acids at the P-site transferring to the amino acid in the A-site. The ribosome then shifts down the mRNA one codon and the process repeats. The tRNA in the P-site is shifted to the E-site and ejected from the ribosome.
Translation, termination The process continues until a stop codon is positioned in the A-site. The stop codon is recognized by a specific release factor that catalyzes cleavage of the protein chain in the P-site. The protein chain is released from the ribosome complex as is the tRNA in the E-site. The remaining components are called the post-termination complex. A protein called ABCE1 binds this post-translational complex, separates the two ribosomal subunits and releases the mRNA. Initiation factors are also recruited by this ABCE1 protein which prepare the small subunit for another round of translation.
Wobble If the pairing between codons and anticodons required perfect Watson-Crick base pairing, the cell would need to have 61 different tRNAs, one for each codon that specifies an amino acid. However, cells often contain fewer than 61 different tRNAs. The explanation for this is that a single tRNA can recognize more than one codon due to non-standard base pairing. This pairing flexibility occurs in the third base position of the mRNA and is known as the wobble position. The image below shows the possible wobble interactions.
Adenine is rarely found in the anticodon wobble position of tRNA. However, a deaminated version of adenine, inosine (I) is found in the tRNA of many eukayotes. Looking at the chart above, you can see that if the tRNA has an inosine (I) base in the wobble position (1st or 5’ position), the tRNA can recognize mRNA with either a C, A or U in the wobble position (3rd or 3’ position) of the mRNA. For this reason, inosine is frequently used in tRNA for translation of synonymous codons that specify a single amino acid. For example, three of the four codons that specify valine (Val) are recognized by the tRNA with the anticodon sequence of 3’-CAI-5’. Test yourself on this concept by identifying the three codons that can be recognized by that anticodon sequence (answer at end of post).
Polysomes Translation of a typical protein takes about one or two minutes. The efficiency of this process can be increased by two phenomenon. Multiple ribosomes can attach to a single mRNA and translate performed simultaneously. These structures are known as polysomes or polyribosomes. The other process that increases the efficiency of translation is the rapid recycling of ribosomes. Because the poly(A) tail interacts with the initiation complex and creates a looped structure, the 3’ end (termination end)of the mRNA is relatively close to the 5’ end (initiation end). When the ribosomal subunits are released from the 3’ end at termination of translation, they can quickly locate the initiation site and begin the process again. Next we will look at the process of DNA replication and begin to explore how mutations arise through this process. HBD Answers - (highlight to make easier to read)
Answer to protein sequence: (part A) Met - Leu - Asn - Arg - Tyr - Lys - His - Gly - Pro - Trp (part B, after mutation) Met - Asp - His - Gly - Asn Answer to wobble anticodon problem: GUA, GUC, and GUU. Whoever calls me ignorant shares my own opinion. Sorrowfully and tacitly I recognize my ignorance, when I consider how much I lack of what my mind in its craving for knowledge is sighing for... I console myself with the consideration that this belongs to our common nature. - Francesco Petrarca "Nothing is easier than to persuade people who want to be persuaded and already believe." - another Petrarca gem. Ignorance is a most formidable opponent rivaled only by arrogance; but when the two join forces, one is all but invincible. |
|||||||||||||||||||||||||||||||||||||||
|
|
Do Nothing Button
Copyright 2001-2023 by EvC Forum, All Rights Reserved
![]() ™ Version 4.2
™ Version 4.2
Innovative software from Qwixotic © 2024
 (1)
(1)