|

Understanding through Discussion |
|
|
Register | Sign In |
|
QuickSearch
| EvC Forum active members: 64 (9164 total) |
|
| |
| ChatGPT | |
| Total: 916,902 Year: 4,159/9,624 Month: 1,030/974 Week: 357/286 Day: 13/65 Hour: 0/0 |
| Thread ▼ Details |
|
Thread Info
|
|
|
| Author | Topic: Questions on Evolution. | |||||||||||||||||||||||||||||||
|
CreepingTerror Inactive Member |
Sorry if these topics have been covered elsewhere, I searched but had no luck.
1. How long do we think that evolution took, from the first "life" to our current state. 2. I know a lot of Creationists like to throw around the improbability of Evolution. Now, I'm not saying that improbability disprooves Evo, but how intellectually honest is the claim that Evo is improbable. Please, don't go into how just becuase it's improbable doesn't mean it coldn't happen, I'm just wondering if it was indeed improbable. 3. Are there fossil records of overlap, lower forms and higher forms existing together. 4. Why don't we have tails? Please, don't hesitate to correct me if I'm wrong, but our Evo tree comes from Chimps, right? If so, why did we loose our tails. So, I'm looking for answers, not trying to bring down Evo. {Added blank lines - Adminnemooseus} This message has been edited by Adminnemooseus, 12-14-2004 01:39 PM
|
|||||||||||||||||||||||||||||||
|
Adminnemooseus Administrator  Posts: 3976 Joined: |
Kind of a hodge-podge topic.
Going to plug it into the "Short Subjects" forum. Let us get the questions answered, and then close the thing down. Adminnemooseus
|
|||||||||||||||||||||||||||||||
|
Adminnemooseus Administrator Posts: 3976 Joined: |
Thread moved here from the Proposed New Topics forum.
|
|||||||||||||||||||||||||||||||
|
Coragyps Member (Idle past 763 days) Posts: 5553 From: Snyder, Texas, USA Joined: |
1. Between 3.5 and 3.8 billion years.
2. It's pretty improbable, I think, but no one knows enough about how it all happened to put numbers on that probability. 3. Sure, if I may take "lower" and "higher" as meaning "early-arising" and "recently-arising." There are still horseshoe crabs and blue-green algae around with us mammals, no? 4. Chimps, gorillas, and orangutans don't have tails - that's part of the definition of all of us Great Apes. Some ancestor of all four of us failed to grow a tail, and there was no disadvantage to their survival in not having one. The lack was heritable, and here we all are, tailless. Welcome aboard!
|
|||||||||||||||||||||||||||||||
|
coffee_addict Member (Idle past 506 days)  Posts: 3645 From: Indianapolis, IN Joined: |
(1) Depends on what you mean by "current state." The vast majority of life on Earth are single celled organisms. So, I'd say that it did not take that long for life to get where it is now.
(2)Whenever someone use the word "improbably," I always ask the question, "can I see the math?" The fact of the matter is we really don't know all the different factors and variables to accurately calculate a mathematical model that describes it. (3)Sure. (4)Um... chimps don't have tails. And we didn't come from chimps. We both are homonoids, meaning we came from the same ancestor. What that common ancestor is/was, we are still not sure. Going back to the tail thing, we lost our tail because of gradual random mutation that turned out to either be advantagious or is just neutral enough that it wasn't a disadvantage. Added by edit. Going back to the probability, or rather the improbability, of evolution, just because something is improbable doesn't mean it never occurred. I could very easily argue that the chance of a hurricane forming in the southern hemisphere is so miniscue that we can conclude that it is impossible. Well, we were proven wrong in 2004 when the first recorded hurricane ever to have formed in the South Atlantic hit Brazil. POWERFUL STORM HITS SOUTHERN BRAZIL COAST (First Hurricane recorded there) Experts are still debating whether to call the storm a hurricane or not. This message has been edited by Lam, 12-14-2004 02:20 PM Hate world. Revenge soon!
|
|||||||||||||||||||||||||||||||
|
Loudmouth Inactive Member |
quote: Are you talking about abiogenesis, the rise of the first life, or evolution, the way in which life changed over time?
quote: Umm, look around. Your own intestinal tract is covered in lower life forms called bacteria. Some of our early chordate ancestors are still alive, such as the tunicates (ie sea squirts). We don't need to look at the fossil record to know that lower and upper lifeforms lived at the same time.
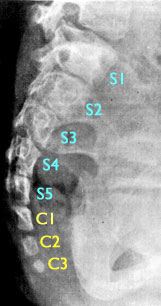
quote: As noted above, the great apes (which includes us) do not have tails. The tail was already gone when we split off from the chimp line. However, some of us do, although it is a rare occurence. It is called an atavism, a relic of our evolutionary past: ABE (C1, 2, and 3 refer to caudal vertebrae, in laymen terms "bones of the tail")
Other example of this phenomena are whales that sprout legs with hooves. This message has been edited by Loudmouth, 12-14-2004 02:15 PM
|
|||||||||||||||||||||||||||||||
|
Coragyps Member (Idle past 763 days) Posts: 5553 From: Snyder, Texas, USA Joined: |
Other example of this phenomena are whales that sprout legs with hooves.
Hi-ho, Silver! Giddyup, Moby! 
|
|||||||||||||||||||||||||||||||
|
CreepingTerror Inactive Member |
Thanks for the quick answers. My bad about the Chimp thing. So can we give a rough estimate to the improbability of evolution?
|
|||||||||||||||||||||||||||||||
|
coffee_addict Member (Idle past 506 days) Posts: 3645 From: Indianapolis, IN Joined: |
Looks like a nobel prize is waiting for you, that is if you can figure out how to make even a rough estimate.
|
|||||||||||||||||||||||||||||||
|
NosyNed Member  Posts: 9004 From: Canada Joined: |
My bad about the Chimp thing. So can we give a rough estimate to the improbability of evolution? Improbability of what exactly? Obviously any one individual organisism is hugely improbably -- pick a number 1 in 10 ** 20 or so? The probability of you is about zero. You are highly improbable. So what? Improbablilty of the path that evolution has taken over the last 3 some billion years? 1 in 10 ** 100 or 1000 or 10,000 maybe? So the particular probablility of the life that currently exists is the improbability of you multiplied by some collossal number. So what. This message has been edited by NosyNed, 12-15-2004 12:09 AM
|
|||||||||||||||||||||||||||||||
|
CreepingTerror Inactive Member |
Well, my point is that if the entire evo process took Approx 3.5 billion years, and the earth has been around for what 4-4.5 billion years then the universe must be rolling it's dice really well. and heck, who knows if the planet was favorable for the rise of Evo during that whole time. (pre the 3.5 bill years).
To me, it seems to come down to a matter of faith. I mean, evolution is still theory. We're not completely sure. Jump me if you want, but that's how I see it. Fine there's a lot of evidence, but we're not completely sure. If you can convince me otherwise, by all means go ahead. Just because I have this opinion now, doesn't mean that I'm closed minded. Edit:and lam, thanks for the intellectually cloaked, you're a dumbass remark. This message has been edited by CreepingTerror, 12-14-2004 04:40 PM
|
|||||||||||||||||||||||||||||||
|
Loudmouth Inactive Member |
quote: If you have limited resources and an imperfect replicator, the chances of evolution occuring are 1 in 1.
|
|||||||||||||||||||||||||||||||
|
crashfrog Member (Idle past 1496 days)  Posts: 19762 From: Silver Spring, MD Joined: |
To me, it seems to come down to a matter of faith. I mean, evolution is still theory. We're not completely sure. Jump me if you want, but that's how I see it. Fine there's a lot of evidence, but we're not completely sure. Well, we don't get completely sure in science, because that precludes any ability to change your mind, later. We're still not completely sure that germs cause disease, or that matter is made of atoms, or that gravity is actually universal for all matter. But we're as sure about evolution as we are about those other things, which are still theories too. I don't see any faith involved. Evolution explains the evidence and makes predictions that have been successfully tested. Where're the faith, then, in saying "evolution is the best explanation for the history of life on Earth that we have?"
|
|||||||||||||||||||||||||||||||
|
coffee_addict Member (Idle past 506 days) Posts: 3645 From: Indianapolis, IN Joined: |
CT writes:
Well, it's not as simple as rolling your dice until you get what you need. Well, my point is that if the entire evo process took Approx 3.5 billion years, and the earth has been around for what 4-4.5 billion years then the universe must be rolling it's dice really well. and heck, who knows if the planet was favorable for the rise of Evo during that whole time. (pre the 3.5 bill years) For example, would you say that if you have in your possession 10 dices then the probability of you rolling and getting all 6's is very low? Now, what if everytime you get a 6 then you can put that 6 over to the side and keep rolling the other ones? Say that you have one 6 out of the 10. You put that one 6 over and you keep rolling the other nine dices. Whenever you have more 6's, you just keep those 6's and only keep rolling the ones that you haven't had a 6. If you keep doing this, you will eventually have all ten 6's in a relatively short time. Evolution works like that. The traits that are advantageous to the survival of the organism is kept through natural selection. After many generations and many individual beneficial mutations that are kept through natural selection, you will end up with an organism that seemed to have gotten there by design. So no, it's not as simple as just rolling dices like you said. It's rolling dices and keeping the ones that you want.
To me, it seems to come down to a matter of faith. I mean, evolution is still theory. We're not completely sure. Jump me if you want, but that's how I see it. Fine there's a lot of evidence, but we're not completely sure.
I'm gay, so you wouldn't want me to "jump" on you. Evolution is not just a theory. It is both a scientific theory and fact. Yes, it is an observable fact. About the scientific theory part, you have to understand that in order for something to be recognized as a scientific theory, it must have lots and lots and lots of evidence. In other words, the scientific community is 99.9999% sure that it is true. It's that .0001% that is uncertain, which makes it a theory. Would you doubt gravity? Would you say that things sometimes fall up instead of down (assuming there is no outside influence involved)? The theory of evolution is just as prominent as gravity, germ theory of disease, you name it. It is not something that you take in by faith.
If you can convince me otherwise, by all means go ahead. Just because I have this opinion now, doesn't mean that I'm closed minded.
The problem here is not whether we can convince you or not. The problem is whether you can understand any of what we will present to you. Do not take this as an offense, but the truth is you are ignorant of this subject just like I am ignorant of the field of geology. These are things that take much more than a life time to study. If it were as simple as posting 10 posts and adequately present enough evidence to show why the theory of evolution is a valid scientific theory and fact, everyone would be a doctorate in whatever field they choose. Here, we debate about the specific things about evolution. However, noone can teach you the entire theory on this board. You will either have to read some books or take some classes on it.
and lam, thanks for the intellectually cloaked, you're a dumbass remark.
Hahaha. Easy there. And it's Lam, not lam.
|
|||||||||||||||||||||||||||||||
|
CreepingTerror Inactive Member |
Fair enough, the good traits do get passed on. But that doesn't change the fact that the chances of a mutation having a beneficial effect are extremely low. So fine, you roll a D10**10 and set it aside everytime you get pi. That's still a lot of roles(I think I'm exagerating, but you get the point).
And as just as unlikely (I'll admit some ignorance on both of these topics) is the perfect combination of molecules to give rise to life. Which leads me to another question. Have scientists been able to replicate this process (molecules to amino acids to life)to any extent. I vaguely remember hearing that they had, but I'm not sure. And I'm not even sure if that's the right chain. And in reply to what CrashFrog said, saying that Evo is the best theory is like saying that I am the best Scott Heyer who lives at 359 Allegretto Cres in Saskatoon. What other scientifically viable theories are there that contradict Evo.
|
|||||||||||||||||||||||||||||||
|
|
Do Nothing Button
Copyright 2001-2023 by EvC Forum, All Rights Reserved
![]() ™ Version 4.2
™ Version 4.2
Innovative software from Qwixotic © 2024